Supervisor: Dr. Albert Ting Leung LEE
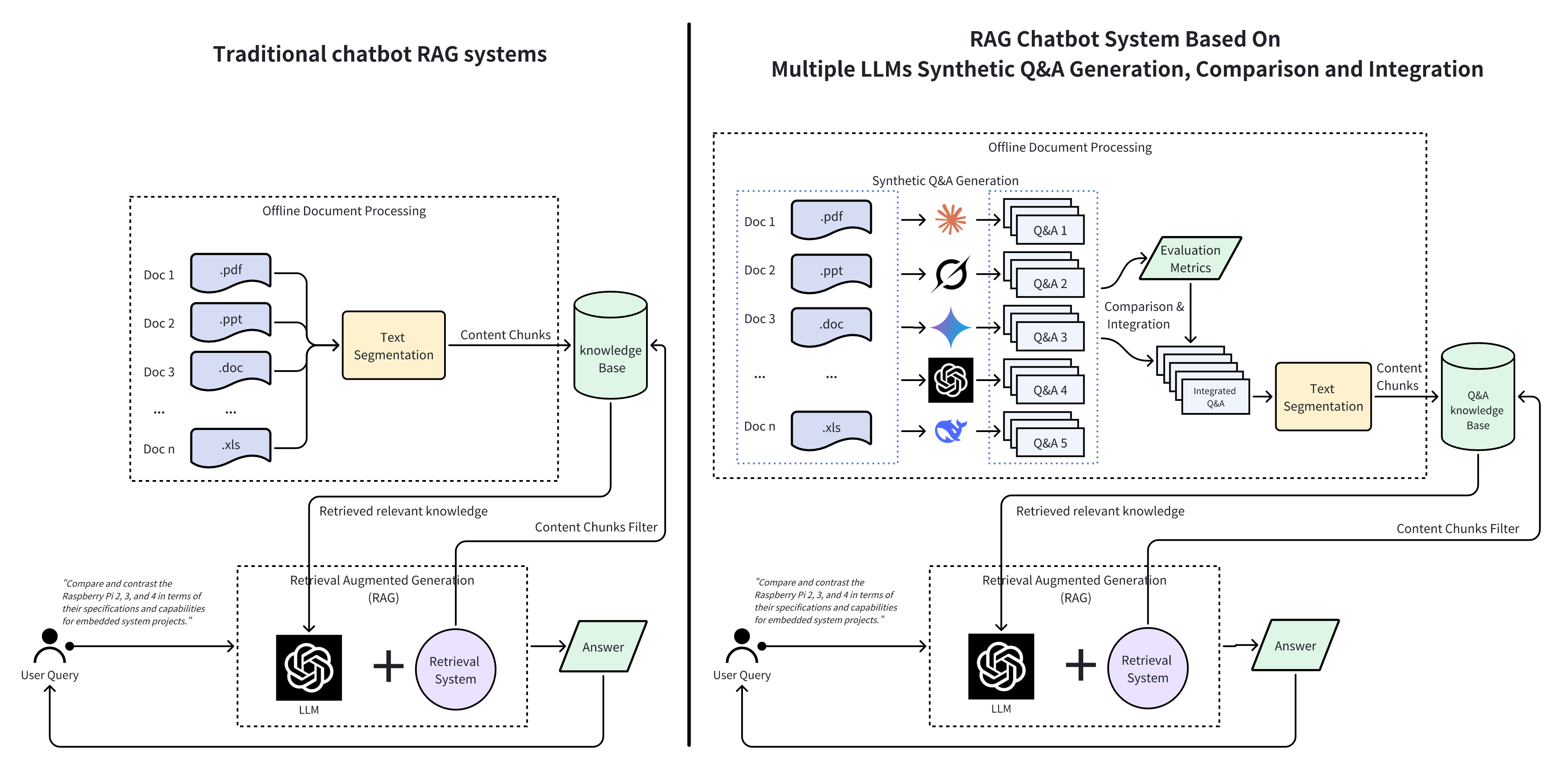
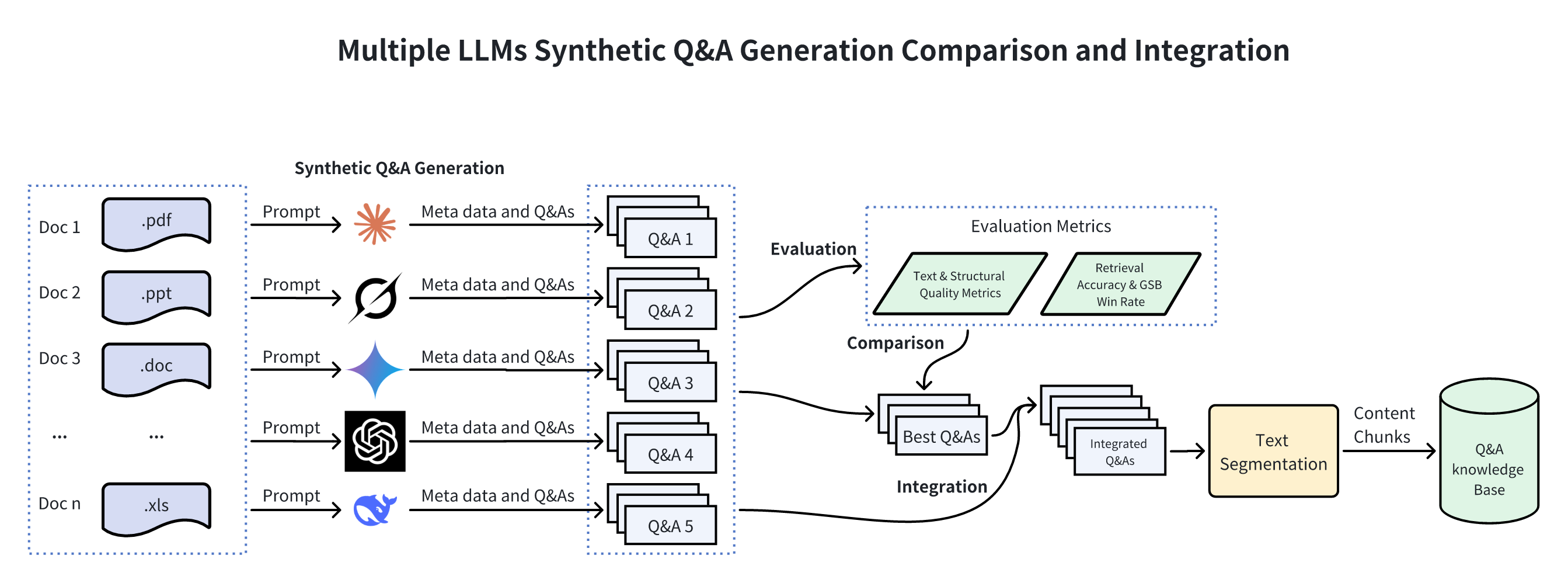
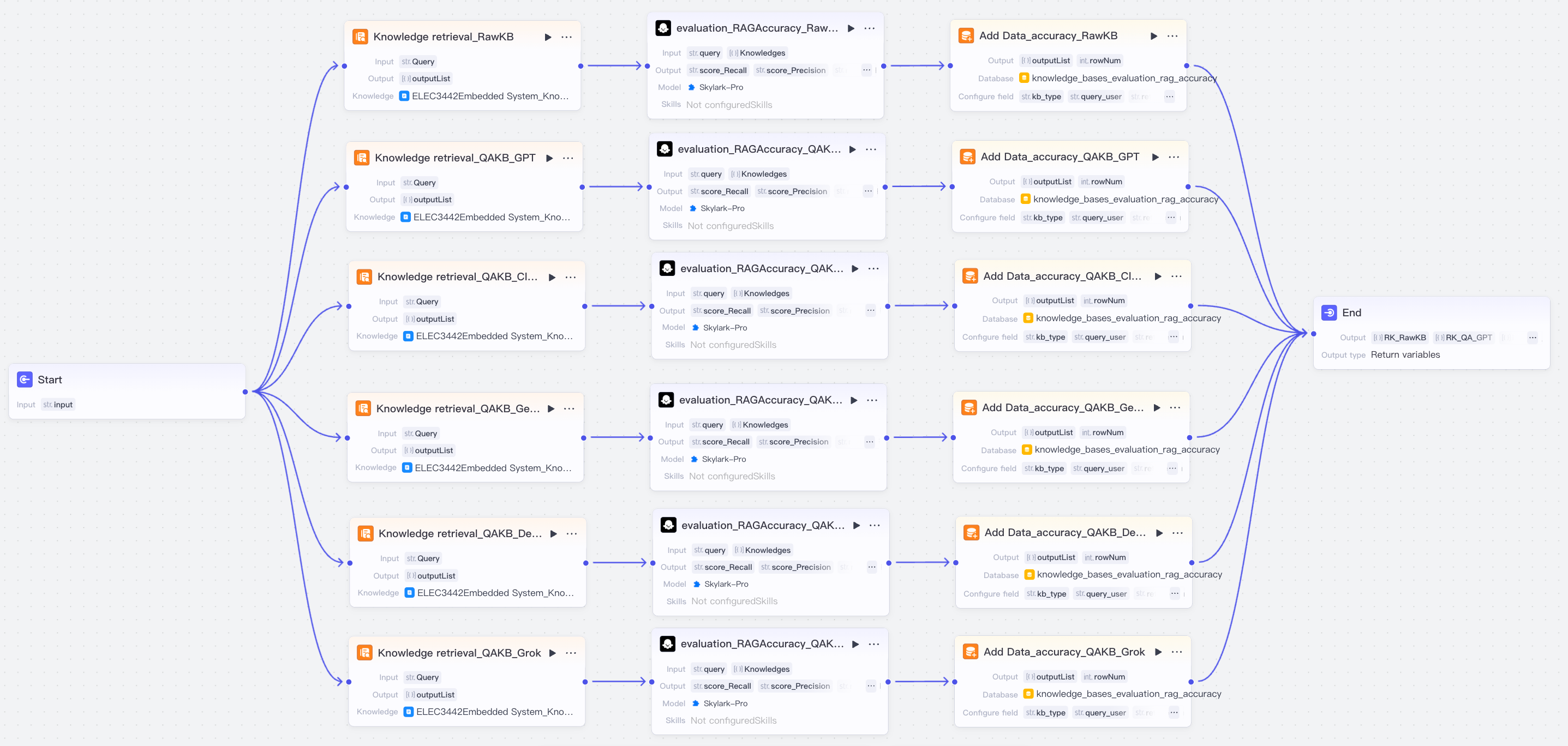
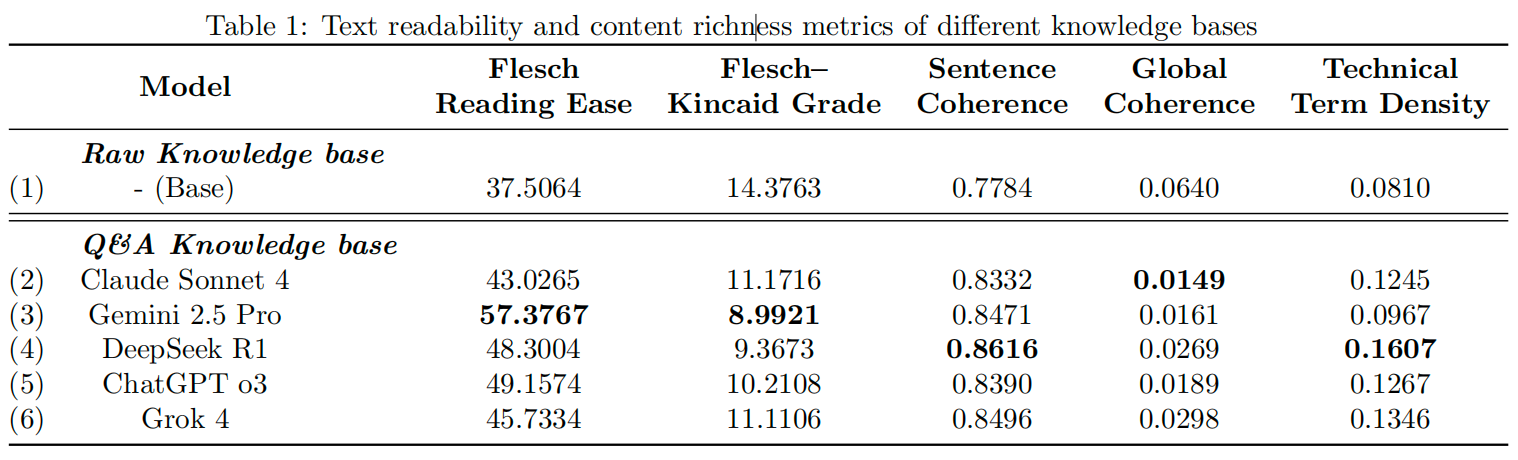
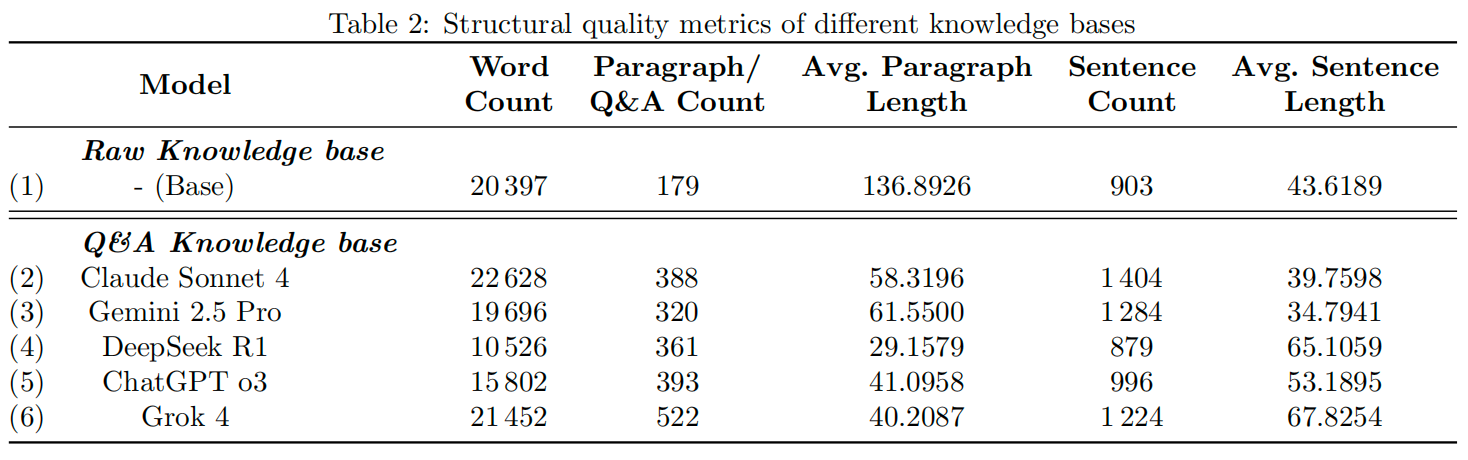
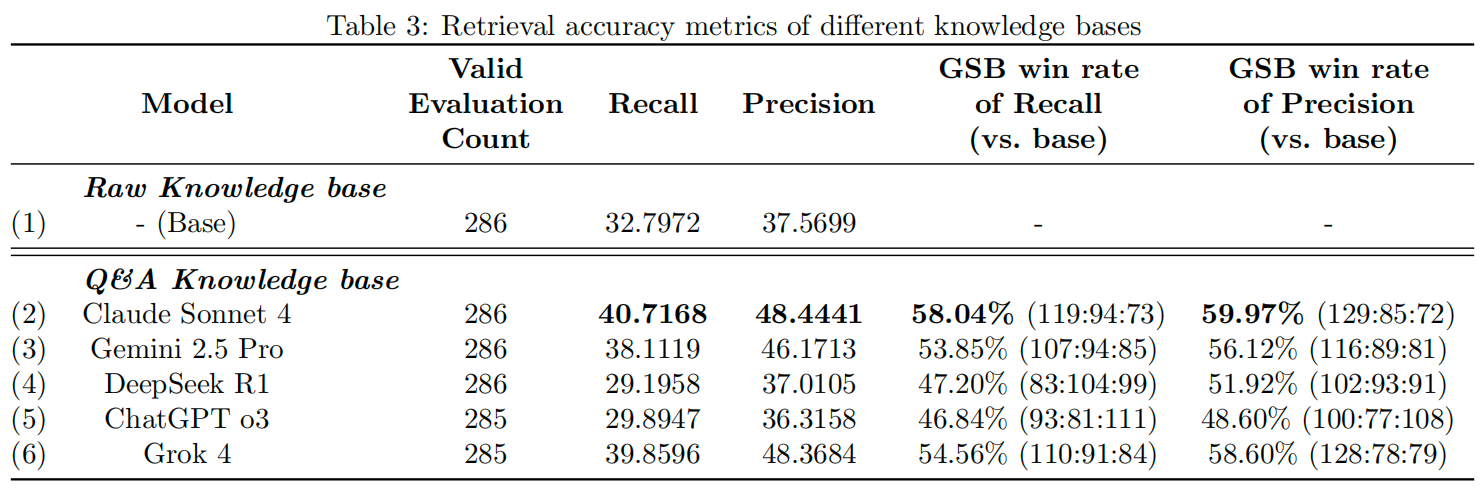
Comparison of the system architecture diagrams of a traditional Retrieval Augmentation Generation (RAG) system and a RAG Chatbot System Based On Multiple Model Synthetic Q&A Generation Comparison and Integration. Prior to inference, knowledge is extracted and augmented based on course document content using Multiple LLMs and a high quality Q&A set is generated for downstream retrieval.
Background & Objective
Current Challenges
- Traditional RAG systems suffer from heterogeneous document formats and noise interference
- Improper segmentation strategies lead to low retrieval accuracy
- Severe hallucination problems in course-specific knowledge scenarios
- Limited effectiveness when handling proprietary educational content
Research Objectives
- Construct high-quality course-specific knowledge bases
- Generate structured Q&A knowledge bases through multi-model collaborative knowledge distillation
- Enhance RAG system retrieval accuracy for educational applications
- Validate methodology effectiveness in real educational scenarios

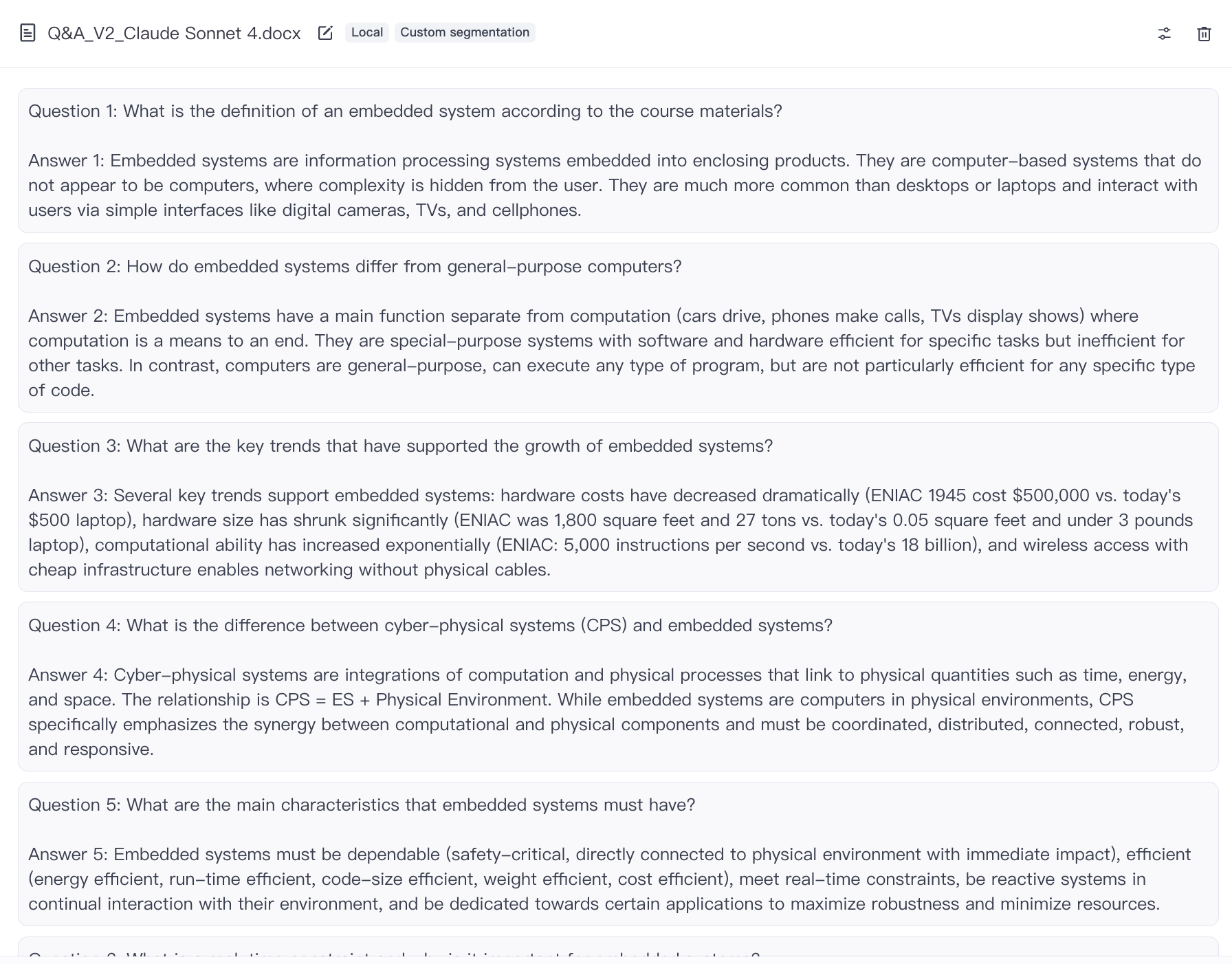
Examples of LLM lacking critical knowledge in Course-specific Queries. When a student asked about ELEC3442 project requirements, LLM gaves generic hardware design steps, not the course-specific details.
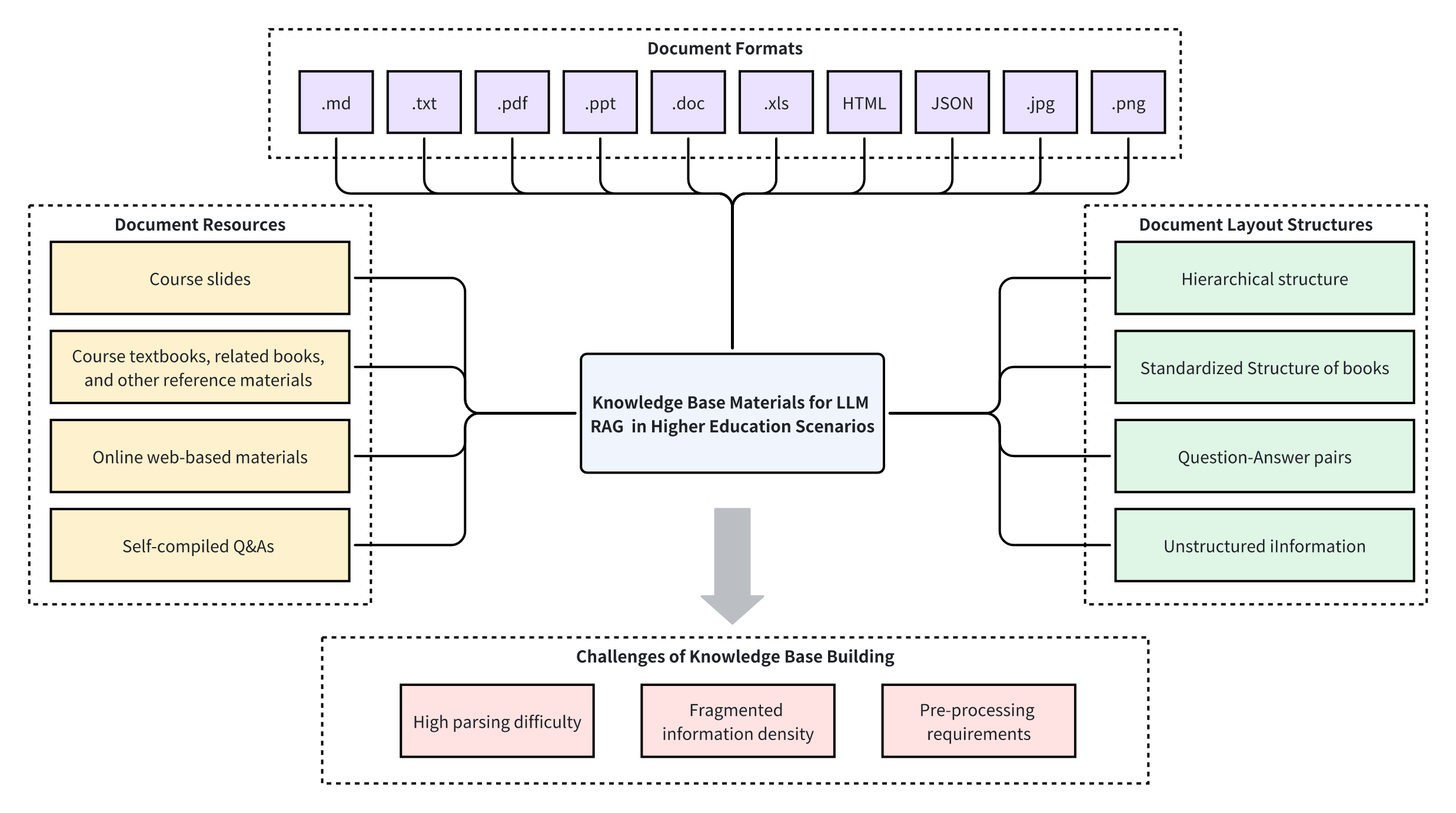
Challenges of traditional RAG systems in the knowledge base building process
传统检索增强生成(RAG)系统与基于多模型合成问答生成比较集成的RAG聊天机器人系统的系统架构图比较。在推理之前,使用多个LLM基于课程文档内容提取和增强知识,并生成高质量的问答集用于下游检索。
研究背景与目标
现有挑战
- 传统RAG系统存在文档格式异构、噪声干扰等问题
- 分割策略不当导致检索精度低下
- 在课程专有知识场景中幻觉问题严重
- 处理教育专有内容时效果有限
研究目标
- 构建高质量的课程专用知识库
- 通过多模型协同知识蒸馏生成结构化问答知识库
- 提升RAG系统在教育应用中的检索准确性
- 验证方法在实际教育场景中的有效性
LLM 在特定课程问题中缺乏关键知识的示例。当一名学生询问 ELEC3442 项目要求时,LLM 只提供了一般的硬件设计步骤,而没有提供特定课程的详细信息。
传统RAG系统在知识库构建过程中的挑战